
The first part of this article brought out the example of creating a model, and familiarized us with the most important steps in ML: data preparation, selection of trait, model training (selection of model parameters), and final evaluation of results (AUC, Precision, Recall, etc.).
Now let’s look at a real example of using Studio to solve a practical ML problem. This project was successfully implemented and is already used for prediction based on cv/opportunity text.
The first thing we need to perform in machine learning is data. All data required for training is stored in Azure Document DB (Cosmos DB). For the improved process of data preparation and future training, we get data and store it into dataset into Azure ML Studio.
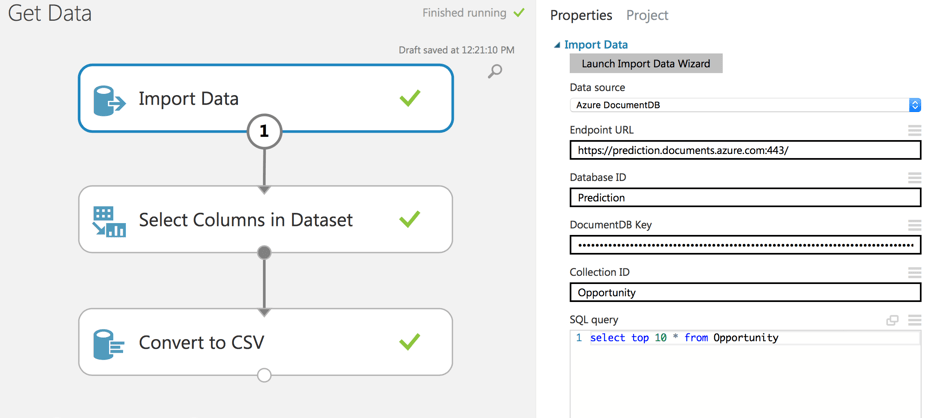
Once the import is done we can visualize it.
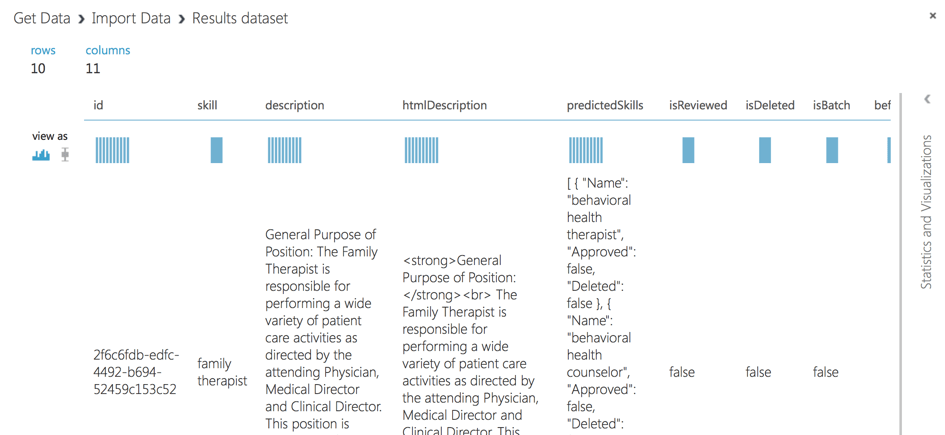
Also, because Document DB contains additional fields, we should select specific fields like skill, description…
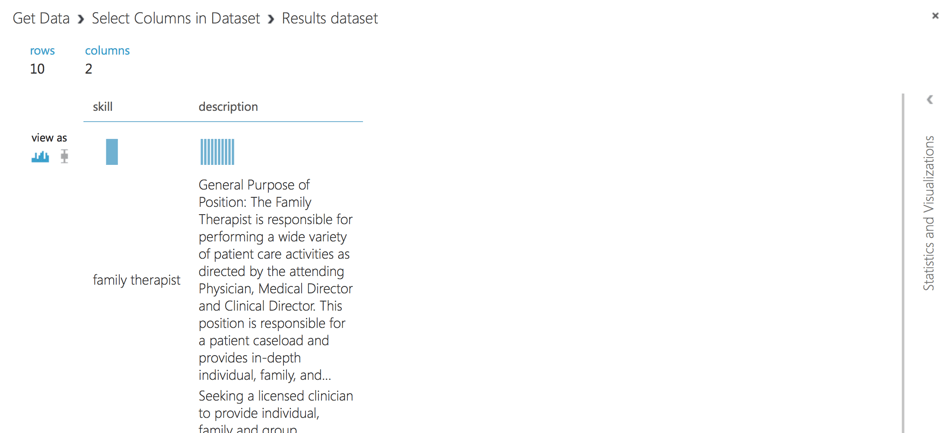
As a final step, we store dataset as .csv into Azure ML Studio storage.
A dataset usually requires some preprocessing before it can be analyzed. For example, we might have noticed the missing values are present in the columns of various rows. These missing values need to be cleaned so the model can analyze the data correctly. In this case, we’ll remove any rows that have missing values. Then, we clean the text using Preprocess Text module. The cleaning reduces the noise in the dataset, helps you find the most important features, and improves the accuracy of the final model. We remove stopwords – common words such as “the” or “a”, numbers, special characters, duplicated characters, email addresses, and URLs. We also convert the text to lowercase, lemmatize the words, and detect sentence boundaries that are, then, indicated by “”|||” symbol in pre-processed text.||
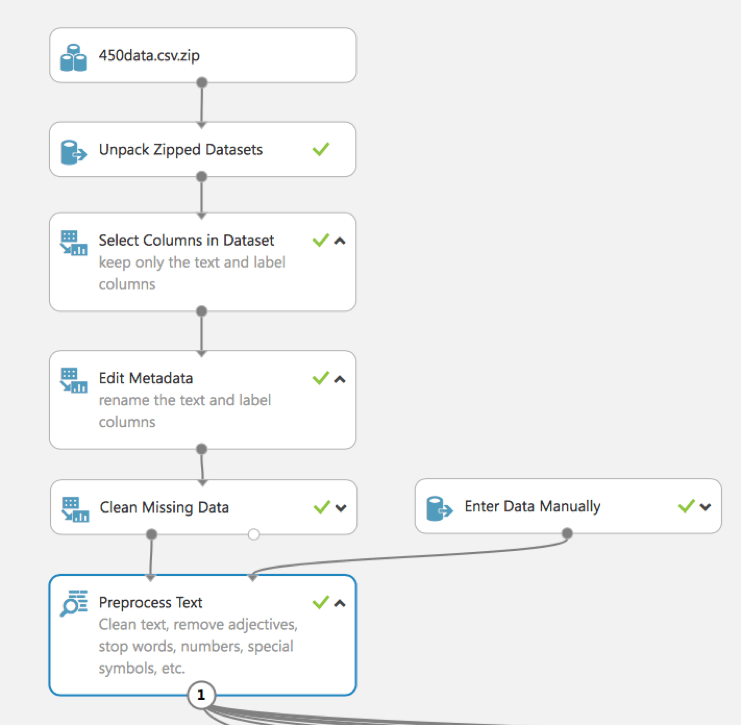
As we see, in this experiment (in contrast to the part 1 example) the built-in module Preprocess Text (previously we showed the use of R script) is used. It allows us to clear the text, to remove stop words, numbers, special symbols, etc.
The main goal of this step is to receive a cleaned text (opportunity description) without stop words, numbers, emails, URLs, etc. For example here is a description before preprocessing:
General Purpose of Position: The Family Therapist is responsible for performing a wide variety of patient care
activities as directed by the attending Physician, Medical Director andClinical Director. This position is
responsible for a patient caseload and provides in-depth individual, family, and group counseling. Counseling
includes the ongoing completion of psychosocial and bio-psychosocial assessments. The Family Therapist collaborates
with the Clinical Team to develop individualized treatment plans and assists in coordinating discharge planning.
This position follows patients' progress from a psychological standpoint, beginning with admittance through
discharge. During this time, the Family Therapist maintains frequent and open communication with the Clinical
Director and Therapists regarding any issues or problems. Primary Responsibilities (include but are not limited to):
Establish individualized family therapy programs, through face to face and/or phone communication with families of
Sunspire Health patients. Conduct and evaluate family assessments...
And after:
purpose ||| therapist perform variety care activity as direct physician | director director ||| caseload | depth |
family | group counsel ||| counsel include completion bio | assessment ||| family therapist collaborate develop
treatment plan assist discharge plan ||| follow patient | progress standpoint | begin admittance discharge ||| |
therapist maintain communication director therapist issue problem ||| | include but limit | ||| | establish therapy
program | face face | or communication family sunspire health patient ||| | conduct evaluate assessment ||| |
conduct family counsel session patient ||| | referral resource patient | family area ||| | coordinate patient |
family patient treatment plan discharge | aftercare plan ||| | basis | coordinate lead retreat consist group therapy
| lecture question answer period | facility | finalization discharge aftercare plan ||| | participate | site
activity that relate therapy ||| | create group group sunspire health facility | focus system issue recovery ||| |
maintain documentation family counsel activity ||| | may ask complete review | utilization review | as ||| | |
college or university psychology | | or field ||| | health set ||| family therapist | | maintain licensure | lcs w |
lmh c | lmf t | aarn p. | acquire licensure ||| |license proof insurance ||| | maintain cp r aid certification ||| |
strong ||| | detail ||| | pressure as as ||| | strong | ||| | structure english language mean spell word | rule
composition | grammar ||| | principle process service ||| include assessment| standard service | evaluation
satisfaction ||| | behavior performance | difference | personality | | learn motivation | research method |
assessment treatment disorder ||| | patient | patient service resolve issue ||| | acumen ||| | car f standard ||| |
problem review develop evaluate option implement solution ||| | logic reason identify strength weakness solution |
conclusion or approach problem ||| | cost benefit action choose ||| | handle priority urgency ||| | communication | |
presentation ||| | | people ||| as||| | other | reaction | understand react ||| as | adjust action relation other |||
| bring other try reconcile difference||
To build a model for text data, we typically have to convert free-form text into numeric feature vectors. In our experiment, we use Extract N-Gram Features from Text module to transform the text data into such format. This module takes a column of whitespace-separated words and computes a dictionary of words, or N-grams of words, that appear in your dataset. Then, it counts how many times each word, or N-gram, appears in each record, and creates feature vectors from those counts. In our experiment we set N-gram size to 2, so our feature vectors include single words and combinations of two subsequent words.

We apply TF-IDF (Term Frequency Inverse Document Frequency) weighting to N-gram counts. This approach adds the weight of words that appear frequently in a single record, but are rare across the entire dataset. Other options include binary, TF, and graph weighing.
Such text features often have high dimensionality. For example, if your corpus has 100,000 unique words, your feature space will have 100,000 dimensions, or more if N-grams are used. The Extract N-Gram Features module gives you a set of options to reduce the dimensionality. You can choose to exclude words that are short or long, or too uncommon or too frequent to have significant predictive value. In our experiment, we exclude N-grams that appear in fewer than 5 records.
Also, we use feature selection to get only those values, which are the most correlated with our target prediction. We use Chi-Squared feature selection to pick 50000 features. We can view the vocabulary of selected words or N-grams by clicking the right output of Extract N-grams module.
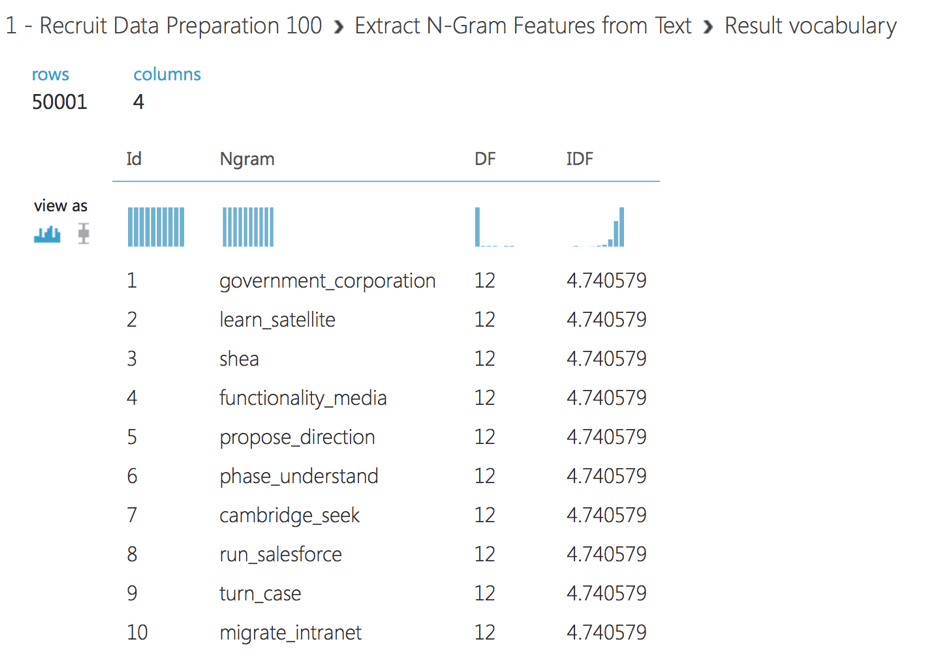
We use the Multiclass Neural Network module to create a neural network model that can be used to predict a target that has multiple values. Also, we use the Tune Model Hyperparameters module to build and test models using different combinations of settings, in order to determine the optimum hyperparameters for the given prediction task and data.
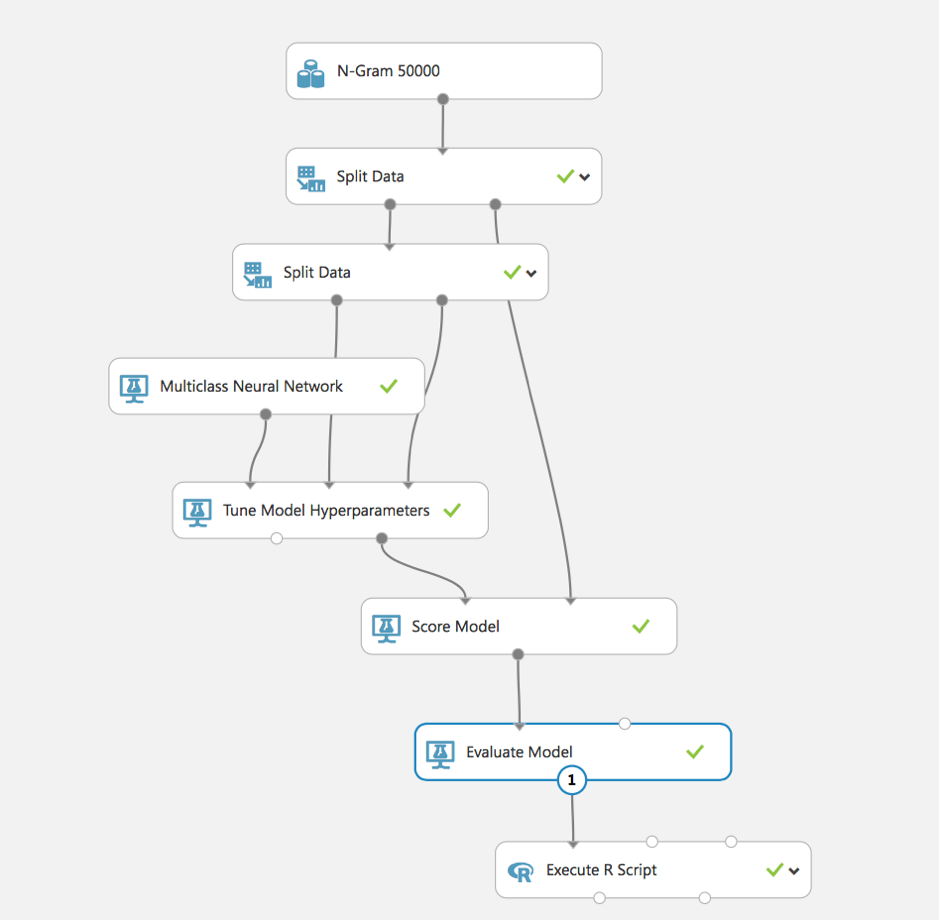
At first, we split data for training and score dataset, it means we select part of data that will not be included in the training process but will be used as test data for calculation of accuracy.
At the second step, we also split training dataset for Tune Model Hyperparameters. After that, we configure the main model of our experiment – Multiclass Neural Network.
After training, we can score and evaluate the model to analyze for analyzing received accuracy.
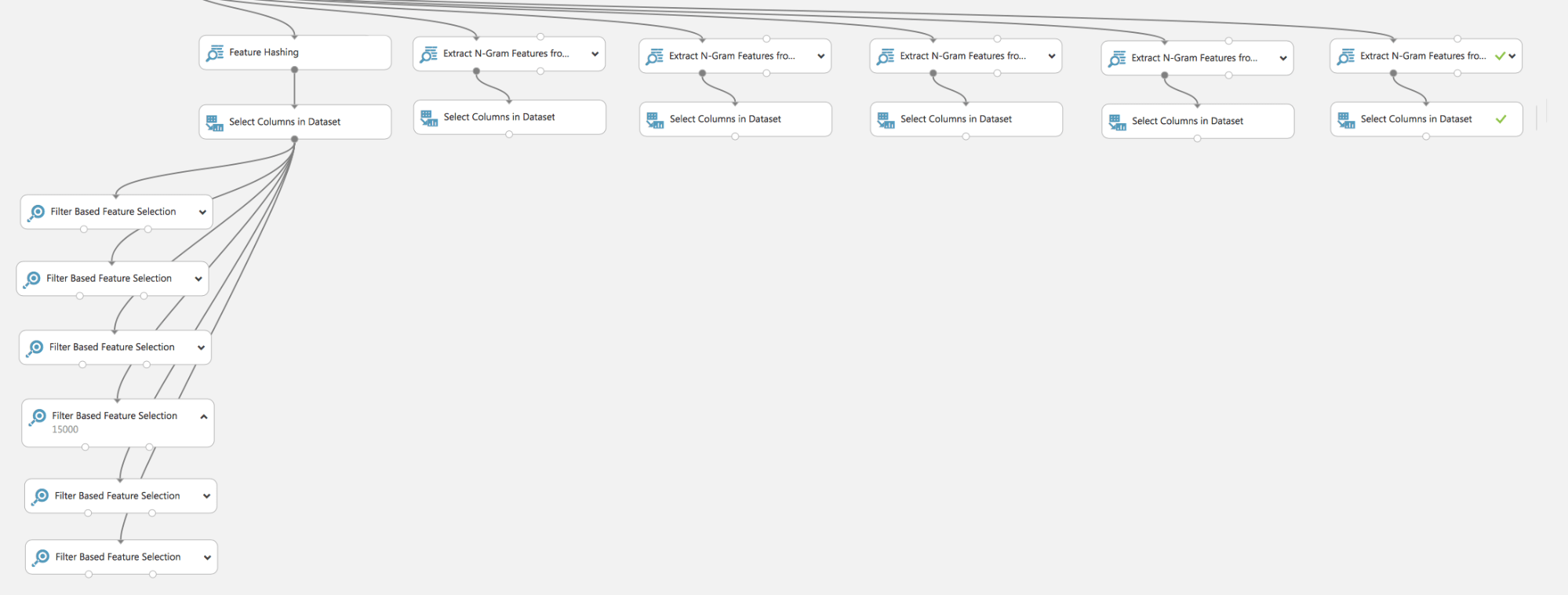
As we see, in a few fairly simple steps, we have built a model for solving a practical problem. Of course, some steps have been omitted, for example, searching for the optimal text processing method TF / TF-IDF and their parameters:
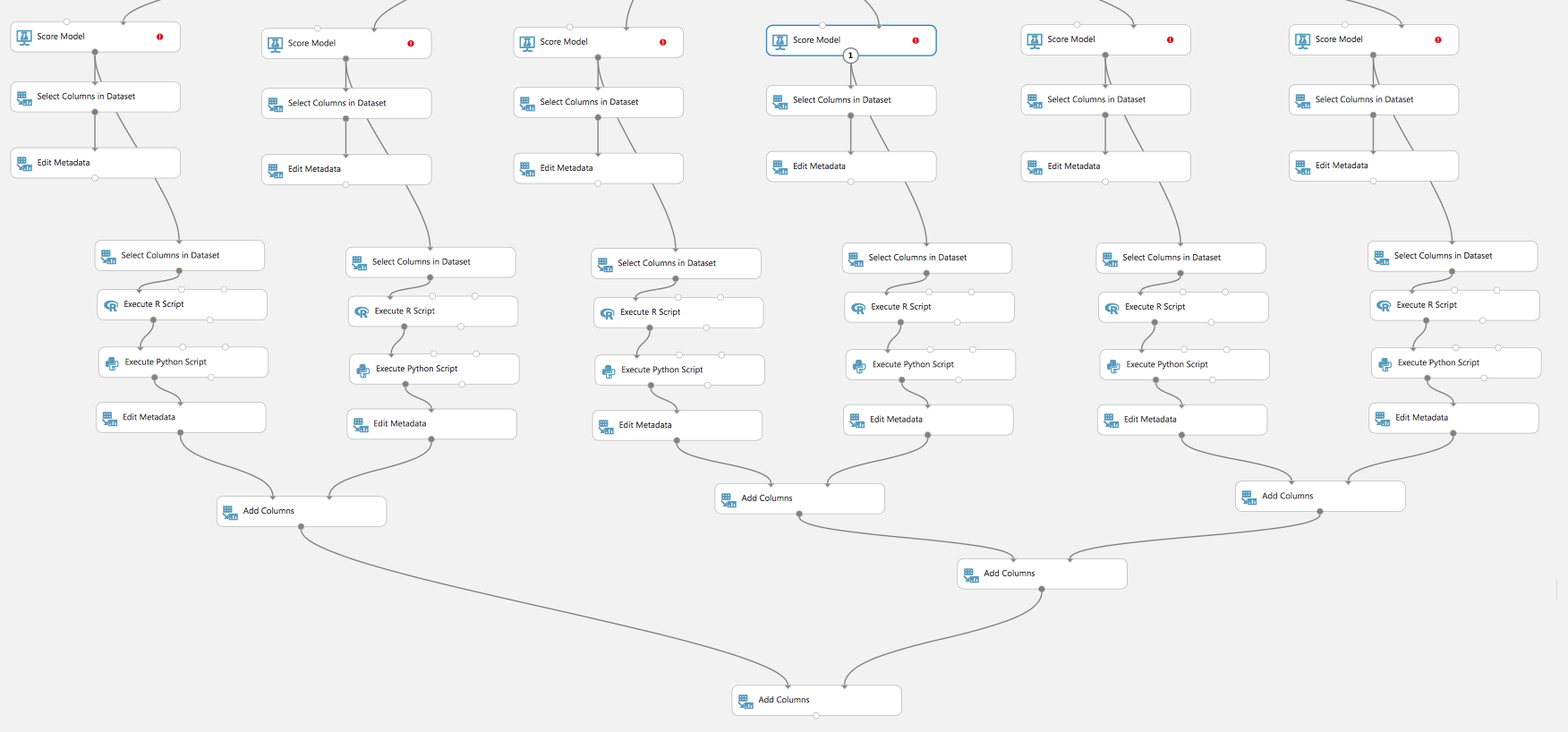
Or comparing the quality of different models:
In this article, we tried to show an example of using ML and Azure ML Studio to solve a practical problem. Of course, we showed it briefly – since the development of models for Natural Language Processing is a topic for the whole book, and the article can turn into a textbook for ML, NLP, Azure ML Studio.
But the main thing is that we proved that it is possible to build such models simply and quickly, having the initial knowledge of ML, the demonstrated tool – Azure ML Studio allows it.
Of course, we did not cover all aspects of ML and ML Studio, we did not consider other types of models, did not show how to effectively select the parameters of models – from simple logical regressions to neural networks. We did not show how to build neural networks with different types of activation functions and multi-layer networks. All these can be exposed in the next article.
About Redwerk
Redwerk is an outsourcing software product development company that is aced in delivering ultimate IT solutions for all-sized businesses. Our focus industries are E-commerce, Business Automation, E-health, Media & Entertainment, E-government, Game Development, Startups & Innovation. One of the fortes we’ve gained within lingering professional experience is providing cloud-computing technology benefits to businesses. We optimize workflow processes and use the best toolkit for these purposes – azure application development service. To unleash the power of state-of-the-art digital capabilities, hire a dedicated team which we thoroughly assembled within years to become a businesses’ day-to-day and strategic issues troubleshooter.


