Web crawlers are programs for mass downloading and processing of Internet content. They are also often called “spiders,” “robots,” or even just “bots.” At its core, a crawler does the same things as any ordinary web browser: it sends HTTP requests to servers and retrieves content from their responses. But what happens after that is another story: while a browser will process and render that content for users to interact with, a crawler will parse it and extract data which meets certain criteria. This includes retrieving links to other pages and crawling them as well. Retrieve page, parse page, process data, find links to other pages, rinse, wash, repeat: that’s a basic crawler in a nutshell.
What is Web Crawler?
Web crawlers are programs for mass downloading and processing of Internet content. They are also often called “spiders,” “robots,” or even just “bots.” At its core, a crawler does the same things as any ordinary web browser: it sends HTTP requests to servers and retrieves content from their responses. But what happens after that is another story: while a browser will process and render that content for users to interact with, a crawler will parse it and extract data which meets certain criteria. This includes retrieving links to other pages and crawling them as well. Retrieve page, parse page, process data, find links to other pages, rinse, wash, repeat: that’s a basic crawler in a nutshell.
Real-world crawlers do much more than that, however. They are used in many different places for many different purposes. For one example, crawlers serve as the core components of search engines such as Google, Yahoo, Bing, and others. These armies of crawlers constantly search, retrieve, analyze, and index content from the web. Thanks to their never-ending labor, you can count on being able to find content matching your interests just by typing your request into a little search box.
Another crawler-crowded task is archiving websites. Advanced crawlers can create complete copies of a website’s content on a regular basis and save them to a repository where they can be retrieved, viewed, and compared with each other, forming a timeline of changes over the course of days, months, or even years. Content stored in this fashion is digitally signed, so it can even be used as evidence in court.
Yet another popular use for crawlers is data mining, extracting information from web content and converting it into an understandable format for further use. A good example of this is the Google AdSense bot, which searches for pages that feature AdSense advertisements and checks them for policy violations.
Web crawlers are also often used for monitoring purposes. Crawlers can automatically check whether websites and web apps are running properly, helping ensure that downtime is minimal and any errors are fixed quickly.
Last but not least, web crawlers are also used for scraping. Most corporate portals don’t provide any easy way to export the content they provide in a useful format, and those that do tend to offer cumbersome interfaces and slow APIs. Such obstacles do nothing to diminish the demand for that data, however, and web crawlers are a perfect fit for the job of extracting it. Specialized crawlers called “scrapers” are designed to get around the anti-crawling measures such portals implement by emulating ordinary browsing behavior, fooling them into thinking a human is browsing the site instead of a bot.
It’s clear from these examples that crawlers are always busy trawling the Internet, but we feel it’s still important to illustrate the sheer scale of work they can do with some numbers:
- A crawler called IRLbot ran on a supercomputer for two months straight. It collected more than 6.4 billion pages over that period, working at an average rate of approximately 1,000 pages per second, and extracted over 30 billion URLs.
- From 1995 onward, Google and Yahoo’s crawlers have indexed over 1 trillion pages combined.
Challenges Of Web Crawling
Crawlers are in high demand, and they can be a lucrative investment. But there are also a number of caveats to keep in mind regarding their operation and upkeep:
High-Level Technical Challenges
- Industrial-scale crawlers are distributed high-load systems with enormous storage and bandwidth demands. You’ll need a fleet of high-end servers to run one, along with a skilled team to implement and maintain it. The more complex your crawler, the more it will cost you in terms of infrastructure and support.
- Web crawling is a competitive field – not just between crawlers and anti-crawling measures, but also between different crawlers in the same lines of work. A naïve crawler will waste precious clock cycles and bandwidth that other, smarter crawlers will spend on processing more relevant content. Without proper optimization, you might as well not bother running a crawler at all.
- Speaking of naïve crawling, an indiscriminate approach to gathering content can have severe repercussions if your crawler scoops up copyrighted material. If you don’t take steps to ensure this doesn’t happen, you could face legal action if your crawler violates someone’s copyright.
With these factors in mind, it’s clear that a basic crawler simply isn’t going to cut it for any real-world application. Developing an effective crawler takes effort and consideration, and it starts with taking the following challenges into account:
Implementation Challenges
Task scale. The Internet is a huge place, and it’s getting bigger by the second. In order to keep up with the most recent (or even relatively recent) data, your crawler needs to be fast and efficient. With all the different things an effective crawler needs to be capable of, this can be tricky!
Content processing. Ideally, your crawler will process every page it needs to, and skip over every page it doesn’t. Sounds like a simple enough requirement, doesn’t it? Unfortunately, it’s all too easy to end up with a crawler that swallows vast amounts of irrelevant content or ignores reams of valuable data. One of the crucial differences between a smart, fast crawler and a slow, inefficient one is how they pick and choose which data to gather.
Caring for the resources you crawl. Bringing the full might of your crawler to bear against every website you come across is a good way to inadvertently DDoS some undeserving victim – and possibly open yourself up to a lawsuit. Don’t be a menace to the Internet: you need to make sure your crawler is able to limit itself based on the maximum throughput of whatever server it’s trying to access.
Dynamic content issues. We’ve already mentioned that browsers and crawlers do very different things with the content they retrieve from servers: browsers process and render, while crawlers parse and extract. This can be an obstacle when a website generates content dynamically, e.g. using JavaScript. Imagine a play where the actors read out the stage directions instead of actually performing them: that’s typical crawler behavior when it comes to scripts. It’s still possible for a crawler to grab content and links generated in this fashion, but be warned there’s a price to pay in terms of performance.
Multimedia content issues. Sites which make use of Flash, Silverlight, and HTML5 present their own unique problem: there’s simply no way for a crawler to parse and extract data from a plugin or a canvas object. What you can do is capture content indirectly: for example, tracking requests made from a Flash container. Each type of multimedia must be tackled separately, and again, this will have an impact on your crawler’s overall performance.
Social media crawling issues. Social networks – Facebook, Twitter, Tumblr, Google+, Instagram, etc. – are a never-ending fount of useful, valuable data. Unfortunately, they present every single obstacle to crawlers described above at once – and then some! It might be tempting to simply cut through the mess through the means the social networks themselves provide and use their client APIs, but those are limited in terms of both the kinds of data you can access and how efficiently you can access it – you’re certainly not going to be able to get a full snapshot using them.
Getting a crawler that’s worth the investment already sounds like an obstacle course, but we’re just getting started. There’s one further task that makes all of the above seem like child’s play, one that deserves a chapter all to itself: crawling protected areas.
Challenges Of Protected Area Crawling
Crawling protected areas is one of the hardest web crawling tasks out there. There are countless different authentication systems out there, and your crawler needs to support every single one – or else there will be huge swaths of content it simply won’t be able to access. Many of our clients have even asked us to implement protected area crawling as a specific feature, but implementing it is easier said than done. Here’s a breakdown of the challenges protected area crawling has to offer:
Crawler Behavior Concerns
The first rule of protected area crawling is as simple as it is vital: tread carefully. Remember what we said earlier about “don’t be a menace to the Internet”? Following every link and performing every action you have access to is a surefire recipe for destroyed data, angry users, and legal action aimed at you and your irresponsible crawler. You have to make sure that your crawler:
- Won’t delete anything that users are allowed to delete (including the user account itself!)
- Won’t try to change user data (usernames, passwords, etc.)
- Won’t perform content moderation actions (e.g. reporting other users’ content)
- Won’t publish content
- Won’t dismiss user notifications
- And so on!
The short version is, you need to find a way to make sure your crawler behaves in a “read-only” fashion. This is trickier than it sounds! Imagine letting a toddler loose on someone’s precious data, one who has no conception of what is or isn’t safe to touch, what can withstand his curious poking and rattling without breaking – and if he’s about to ruin something important, odds are you won’t be able to stop him in time. That’s what naïve crawling of protected areas looks like, and it takes some sophisticated programming to ensure your crawler has a sense of what’s safe to touch and what isn’t.
But enough about potential crawler catastrophes – how do you get it into protected areas to begin with? We’re going to look at some common authorization mechanisms to give you a sense of the scale of the problem at hand:
Authentication Mechanisms
HTTP basic authentication (BA). This is the simplest way to enforce access controls on web resources: no cookies, no session identifiers, no login pages, just standard HTTP headers. Nearly every net library you’ll find out there supports it out-of-the-box, so it’s trivial to support it in your crawler, but the price of this simplicity is the lack of security: BA does nothing to protect transmitted credentials other than encoding them in Base64, which is just one step removed from simply broadcasting them in plaintext. For this reason, BA – if used at all – should be used over HTTPS to ensure some measure of security.
Certificate-based authentication. While the word “certificate” might bring to mind something you would hang on your wall or give as a gift in lieu of cash, here it refers to an implementation of public key authentication. A certificate is a digital document proving ownership of a public key: if the certificate has a valid signature from a trusted authority, the browser knows it’s safe to use that public key for secure communication. Like basic authentication, certificate-based authentication is common enough in net libraries that you should have no trouble supporting it in your crawler, but you do need to obtain valid certificates for every protected area you want to crawl.
OAuth. OAuth is an open authorization standard which allows users to grant sites and apps secure access to their data without having to share their login information. If you’ve ever used your Microsoft, Google, Twitter, or Facebook sign-in to log into a third-party website without a password, you’ve encountered OAuth in the wild. Implementing OAuth support from scratch can be tricky, so we recommend taking advantage of existing libraries, such as Scribe for Java.
OpenID. OpenID is an open authentication standard that allows users to log into websites through a third-party service. Unlike OAuth, which only handles authorization (i.e. granting access to data between sites), OpenID provides a means by which users can authenticate themselves with multiple sites using only a single set of credentials. OpenID is widely supported by existing libraries, making implementation easy.
And now we come to the most common kind of authentication on the web: form-based authentication. This needs practically no introduction whatsoever: the user is presented with a set of fields for entering their credentials (usually a username and password), which are then verified by the server. Let’s take a step-by-step look at a typical form-based authentication process:
- An unauthorized user attempts to access a secure page
- The server responds with a page containing an authentication form
- The user enters and submits their credentials using the form
- The server verifies the submitted credentials
- If the credentials are valid, the user receives an authentication token/cookie/etc. and is redirected to the secure page
And now let’s take a look at a typical authentication form:
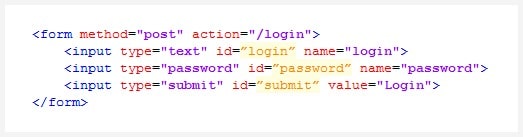
Not exactly intimidating, is it? At a glance, it seems like it would be trivial to integrate authentication via this or any other form into your crawler. It would be as simple as:
- Retrieve and parse the authentication page
- Find the authentication form and extract the endpoint and parameters
- Generate a POST request with the parameters extracted from the form and our credentials
- Execute the request and receive authentication token/cookie/etc. from the server
- Crawl away!
If only it really was that simple! In practice, you’ll run into scenarios like these:
- The authentication form is inside an iframe and only works on the login page
- The authentication form is generated by JavaScript
- The site uses a third-party authentication server
- The authentication endpoint and/or parameters are created dynamically
- The target server domain authority doesn’t match the authentication domain authority
- The request requires dynamic digital signage
Your crawler could end up having to deal with any combination of these complications – like a JavaScript-generated authentication form from a third-party server with dynamically generated parameters that requires a digital signature. That’s not just a hypothetical worst-case scenario, by the way: it’s how the internal corporate portals at McDonald’s used to work!
Another potential authentication complication is “redirect storms”: getting bounced between multiple authentication servers, each of which sets its own authentication cookies. Again, for a browser, it’s no problem at all, but for a crawler, you need to make sure every page is evaluated properly so that you obtain all the cookies and headers necessary for authentication. To cite another real-life example, RJR Tobacco’s corporate portals used to handle authentication this way!
These are just some of the challenges you’ll face when crawling protected areas. Hard-coding solutions for every individual case simply isn’t an option: there are just too many different scenarios to tackle. What you can do, however, is implement a “one size fits all” solution that can be adjusted to handle whatever situation a website might throw at your crawler. We’ll talk about that in the next chapter.
Implementation Approaches
As mentioned in the previous chapter, the best way to handle authentication in a crawler is a “Swiss army knife” approach: rather than a myriad of tools to handle each different scenario, you have a single tool that can handle every scenario. Sounds like a tall order, doesn’t it? It can be – but it’s well-traveled territory, and there’s two tried-and-tested trails through it:
1. On-demand authentication mechanism customization (i.e. scripting).
For this approach, it goes without saying you’ll need to add some kind of scripting support to your crawler. Once that’s done, create a default script – a set of instructions for handling the basic username-password login forms that most websites use. And whenever your crawler runs into something your default script can’t handle (additional hashes, dynamic parameters, redirect storms, etc.), all you have to do is write a custom authentication script to take care of it. Simple!
There’s just two problems with this approach:
- You can’t tell if your crawler is having trouble logging in unless someone reports the issue
- You have to constantly check websites for changes in order to keep your scripts up to date
Here’s yet another real-life scenario to illustrate the issue. Some time ago, Redwerk implemented Facebook and Twitter crawling. Instead of just gathering information using their APIs, however, our crawler was set up to take full, functional snapshots you could actually browse and navigate as if you were on the original site. Not the most efficient way of doing things, and definitely not the easiest way, but we got it working using custom authentication scripts – for all of two months. Facebook and Twitter changed their authentication systems, and we had to rewrite our authentication scripts to match. It’s been a constant cat-and-mouse game since then: every now and then they tweak their authentication, and we have to revise our scripts to work with the new setup. For whatever it’s worth, scripting was the best and likely only way to achieve what we accomplished, but it comes with its cost in terms of maintenance!
2. Browser engine-based services
An alternative approach is to create an authentication service built using a browser engine or web toolkit such as PhantomJS, CasperJS, or Node.js. Considering all the problems that crop up because of the differences between how crawlers and browsers process websites, it only makes sense to deal with one of them by bridging the gap between the two: barring any severe anti-crawling measures, a browser engine-based authentication service will ensure that websites will work exactly the same for your crawler as they will for users. Even Flash and HTML5 content will work perfectly for your crawler!
The process is simple: your crawler polls your authentication service before trying to crawl a protected area of a website, and your service handles whatever login process is required.
You can also include a re-authentication mechanism which will allow your crawler to automatically renew its authentication if it expires for some reason. The functionality your service should provide includes:
- Serving crawler requests to perform authentication (usually done using a REST API)
- Performing said authentication using the parameters received from the crawler (login URL, credentials, timeouts, etc.)
- Gathering and serving back relevant authentication results (cookies, headers, tokens, etc.)
- Ensuring authentication data is unique and not shared between tasks (you wouldn’t want someone to end up crawling your profile, would you?)
With browser engine-based authentication, you don’t need a custom solution for every unusual situation (though you’ll still have to implement ways to handle the myriad edge and corner cases out there). Another benefit is that you can set up a notification system which will inform you when – and why – your crawler can’t log into a site.
And now that you have a browser engine-based service, why stop at just authentication? Your service can do other things that can make your life easier: for example, tracking server requests and extracting resources, making it trivial to grab dynamically generated content. You can even implement your crawler’s entire functionality in this fashion, but it’s not a simple task, and it might not be worth it depending on your crawler’s purpose.
Both approaches have their advantages in different circumstances. Don’t let yourself get locked into one or the other: loyalty to any particular tech stack isn’t going to help you get your job done.
Summary
We’re well aware this isn’t the end-all, be-all of guides to web crawlers: you’re free to disagree with anything we’ve said on the subject. That said, this guide is based on our own experience working with crawlers, and our advice is based on solutions to problems we’ve encountered. We hope that it will at least help you avoid some of the pitfalls that newcomers to web crawling commonly encounter. Crawlers are complicated systems, but if you handle them properly, you can achieve amazing results.
About Redwerk
Redwerk company specializes in providing quality software development services for various industries. One of our strengths is providing companies with data mining and web crawling software solutions, aimed to gather the information for strategic decisions and improving business processes. Redwerk team is always ready to develop new and upgrade existing products for our clients.
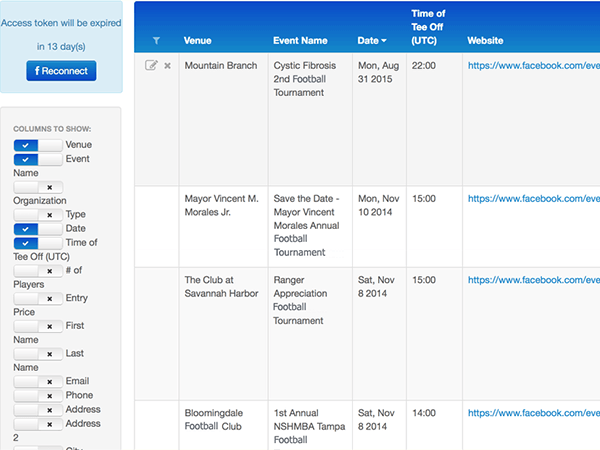
Automated Web Crawling Projects We Have Done
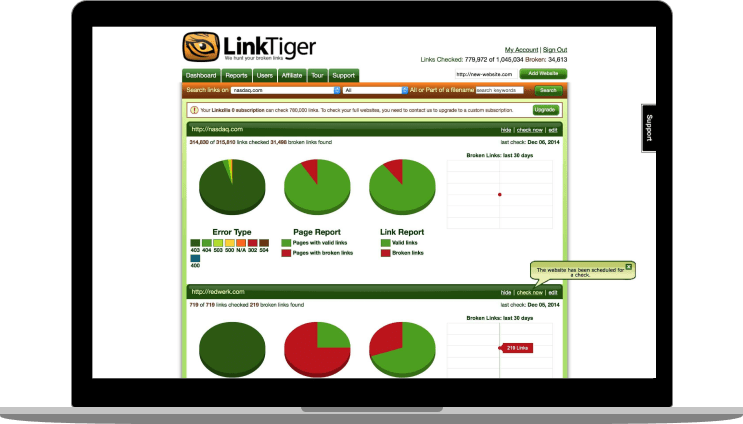
Hear From Our Customer
«Redwerk is a skilled IT Service provider specializing in complex application development, QA and support. Their team is highly skilled, on-time and usually on-budget. They have a cost-effective deployment model and serve the technical and business needs of LinkTiger. I have recommended their services to many business colleagues and they have thanked me for that.» — Steve Moskowski, Owner at Linktiger.com
See how we developed a high-performance crawling system from the ground up