Sports Events Crawler




Customer is a company, which provides professional sports software solutions.
All CustomersProduct Development
Redwerk has created this automated sports tournaments crawling solution from scratch. Our professional team has worked on every phase of the process: analysis, design, development, testing, deployment, maintenance, and support.
Learn moreData Mining
We perform scraping of websites and social network APIs as big data after their automatic processing to render archived websites back to users.
Learn moreChallenge
The client company provides the know-how to assist sports operators in attracting events like local, regional and nationwide tournaments. While its custom software solutions use cutting edge technology, not all of the process steps were optimized. Search and data acquisition, for example, was based on an entirely manual process and therefore in drastic need of an overhaul. All searching, storing, and processing of data had to be carried out manually, which was only effective until a certain amount of data was reached. It was therefore necessary to automate this workflow, which is where the flexible software experts of Redwerk came into the picture.
Out task was to automate the original, manual algorithm used by the client, which was structured more or less as follows:
- Searching for key terms.
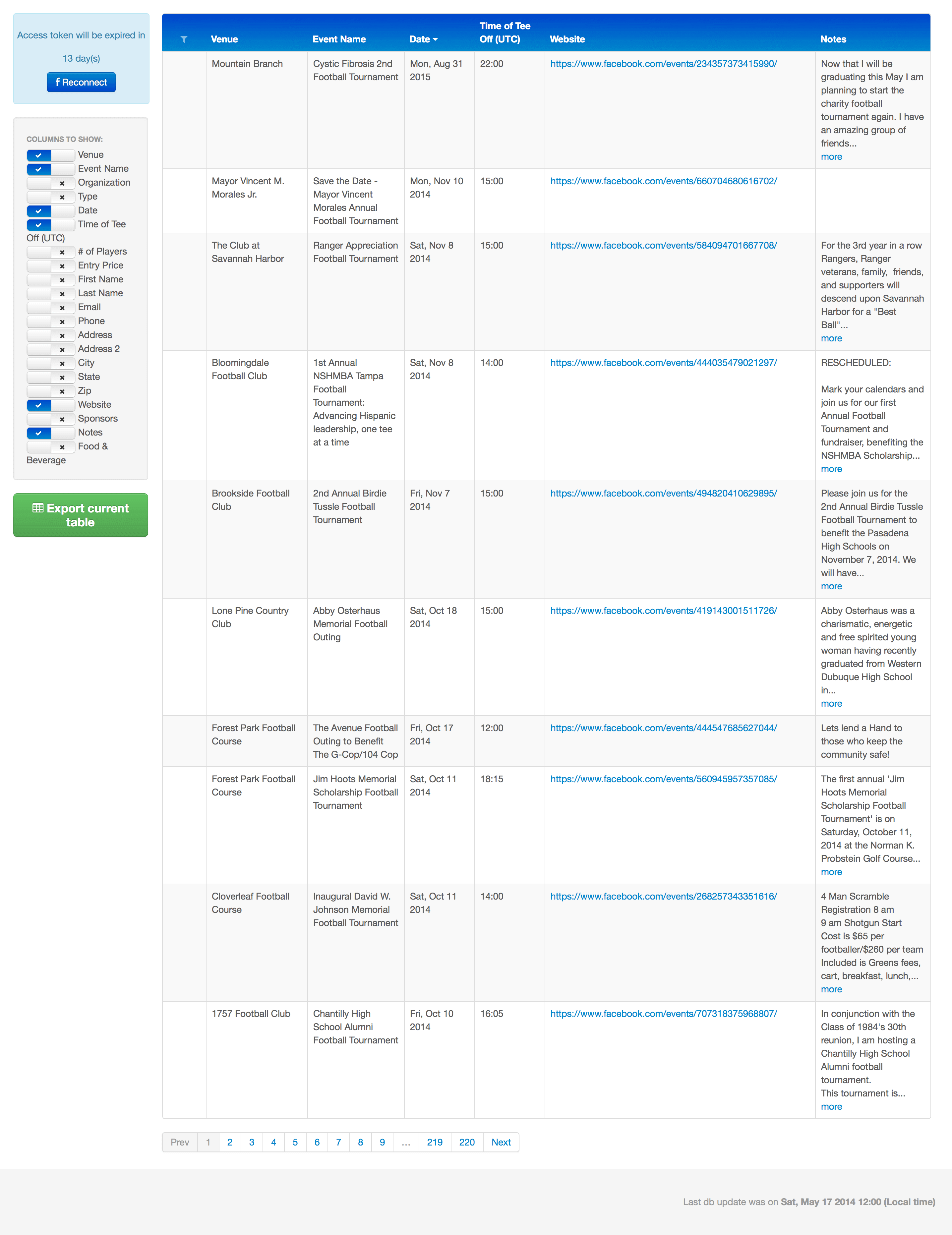
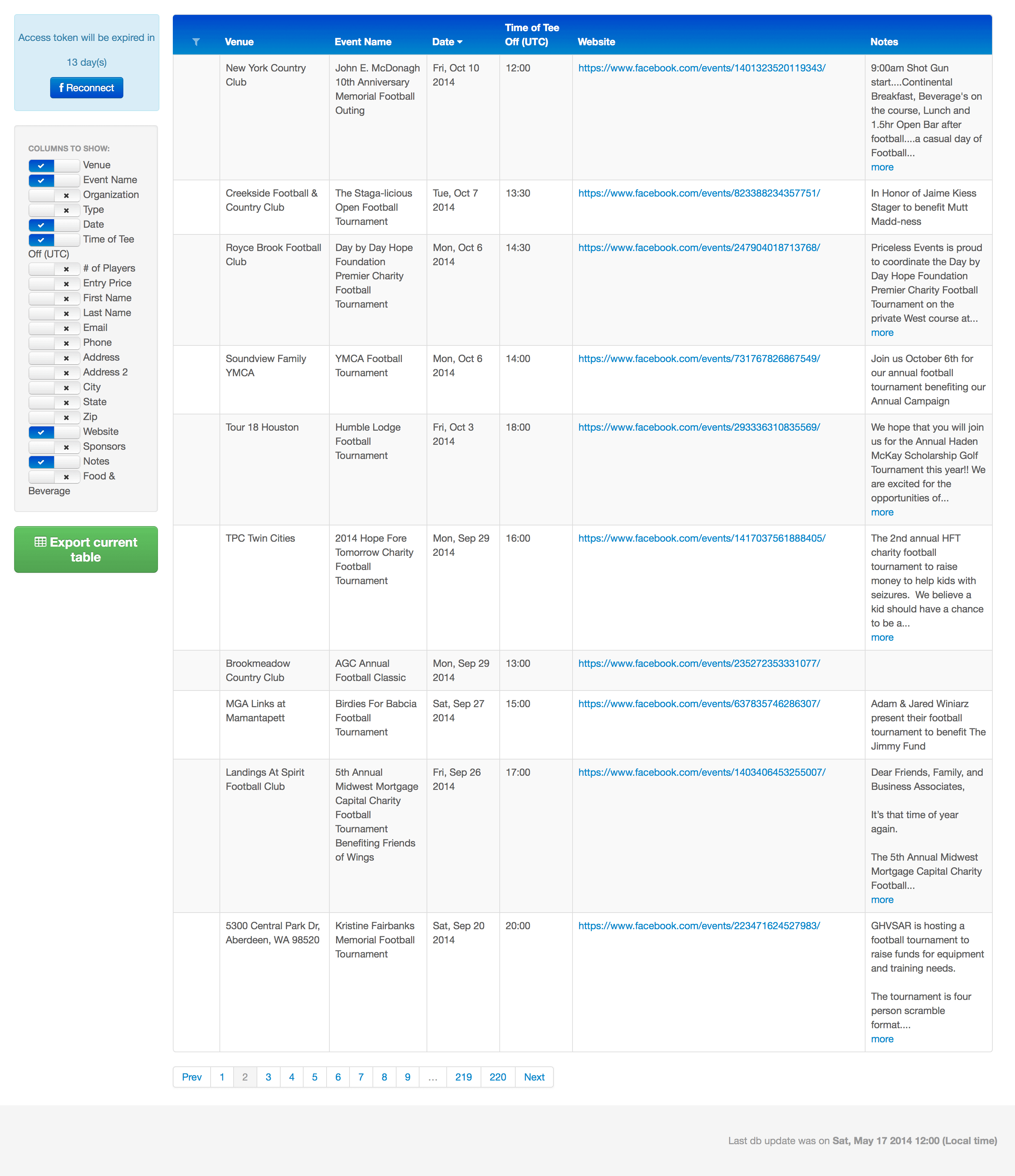
- Compiling search specifications and results: search term, search date, page of the search, title, URL, type, snippet, cache image, cache details.
- Extracting the most important information from snippets, titles, URL’s, etc. Assigning these to the associated search result.
- Recognizing and sorting the extracted data into categories.
In a nutshell: Redwerk was tasked with developing a solution, which combined automated web searches and web crawling. Additionally, we were asked to build a data storage solution in order to be able to sort information and run queries.
For the end user, this means that the software makes it now easier to find tournaments and events and to get all the relevant tournament information and contact details.
Our Research
Redwerk faced a difficult task because all information had to be found, parsed and structured automatically. This made it difficult to apply deterministic approaches for the quick retrieval of information. The required analysis methods would have been very complex to implement, and it soon became apparent that deterministic algorithms were not suitable to process pages of random structures.
Only if we modified the initial point of departure by assuming that there is a finite number of sources from information must be pulled, such an approach becomes justified because of the relative simplicity and determination. Despite the fact that data-mining random information is a very interesting task and can bring some benefits, for this particular technical solution it did not seem suitable. If the application was unable to guarantee a certain amount of data to be found with high accuracy, it would be of no use.
Redwerk’s team evaluated various approaches to this software challenge.
Data-Mining
This method would have been a direct automation of the client’s existing workflow. To extract data, this method required the analysis, the understanding and the interlinking of parts of natural language. While humans see nouns, verbs, names, addresses, etc. on a web page, machines will see only strings and numbers. To build a self-educating system which can carefully understand natural language is one of the most challenging tasks in IT.
Even if we considered a much simpler system for this particular solution, which would be gradually “taught” to gather data from different types of websites through a simple interface, this approach just did not seem to work out for our client.
Pros:
- Most advanced and prospective solution, large amounts of data collected over time
Cons:
- Time-consuming implementation
- Complex algorithms
- Resource-intensive
- Most expensive solution
Social Networks
Social networks are hugely popular and have a massive audience, which is why they are becoming ever more popular with advertisers wanting to draw attention to specific events. As the most popular social network in the world, Facebook was chosen as the object of our research. We evaluated how widely this type of event was advertised on social networks, what amount of useful data could be retrieved, and how fragmented/reliable this data would be.
The results of our Facebook study were mostly positive. Many sports tournaments are posted on Facebook, and new events are added constantly. Thanks to Facebook’s API, it is easy to collect and process data from the social network.
Pros:
- Fast-growing database of events
- Easy data collection and processing through API
- Easiest and fastest solution to implement
Cons:
- No event categorization
- Not particularly sport-specific
- Incorrectly entered information (city specified as event venue, for example)
Data Aggregation
Another approach to collecting information about upcoming sports events is to retrieve information from specialized sports websites. These are designed to provide information on subject-related events in a convenient form, which makes data gained from these sites very valuable for our client’s purposes. Some have subscription systems and provide APIs for easy data access, which allow for a fast implementation of data collection and processing.
However, our research focused on a scenario where no commercial data sources are used and as much data as possible has to be collected “for free”. Under this premise, we would have had to develop web crawlers to download, analyze and extract data from the source code of HTML pages.
Pros:
- Biggest amount of accurate and relevant data
Cons:
- Individual approach required for each website
- Data extraction is often made difficult by webmasters
- Costs and development times grow with the number of websites unless APIs are used
Our Solution
Considering the various advantages and disadvantages of the above-mentioned approaches, it was decided to use not one of them, but a combination of the last two approaches, Facebook data analysis and data aggregation. Using existing aggregators as our primary data source for information about upcoming events seemed to be the most beneficial method in terms of the amount of retrieved valuable data, if approached carefully. Additional information is also pulled from Facebook by our custom solution.
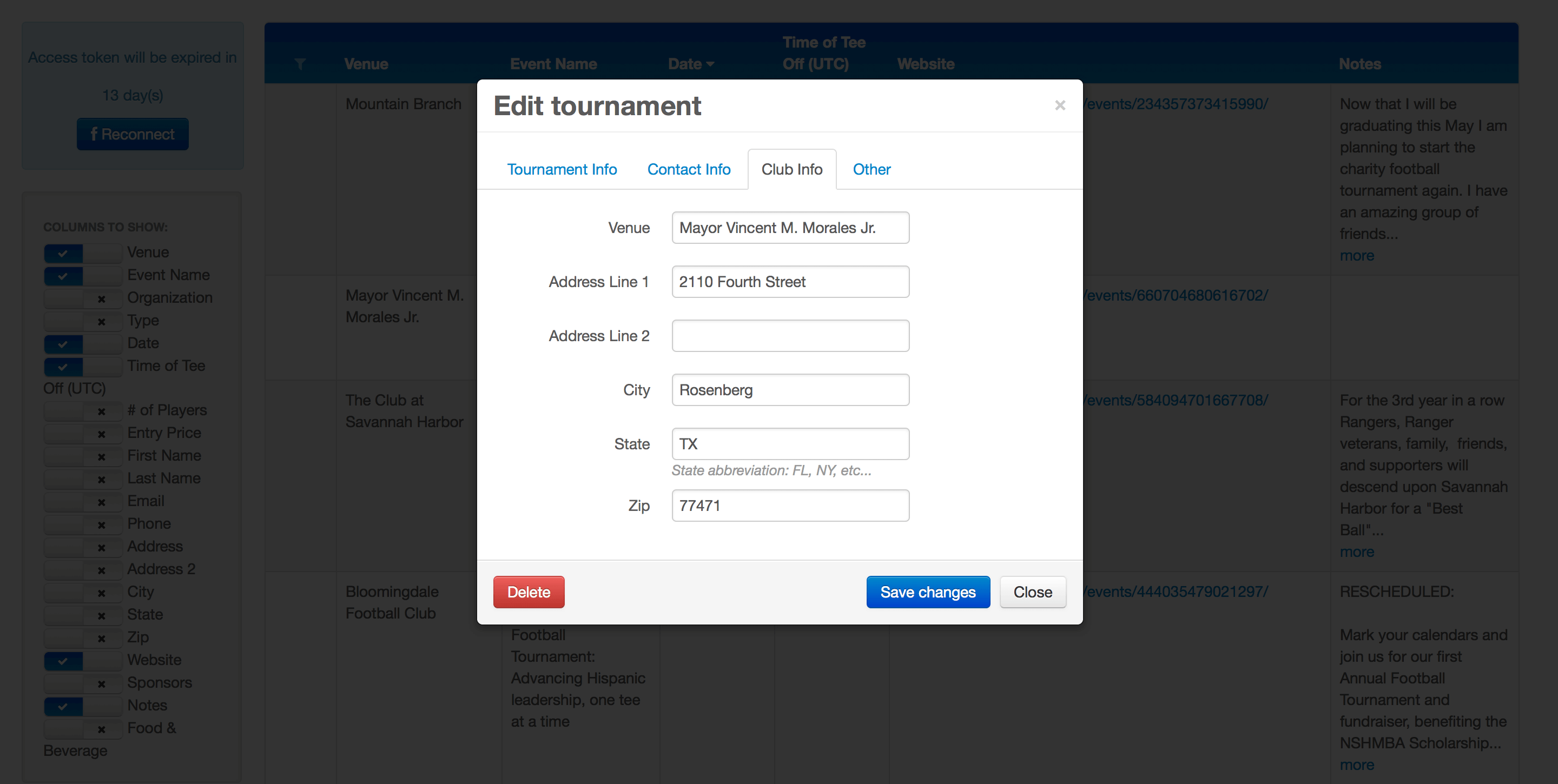
Thanks to the automated web crawling software processes implemented by Redwerk’s engineers, this solution allows filtering and searching sporting events according to a number of different criteria. It shows links to the relevant pages, which the information was obtained from (Facebook event pages) and other types of information and it allows for easy editing and/or deleting of specific events.
Result
Redwerk’s team soon realized that is was very difficult, cost-ineffective and time-consuming to merely replicate our client’s manual algorithm of our customer with automated processes. Instead, we focused on implementing a search structure with a fixed set of data sources, of which Facebook was used in the prototype. This kind of system was much easier to implement and maintain and met the initial requirements perfectly.
With this solution, Redwerk managed to save its client valuable time and money, and our engineers found an elegant solution to a tricky problem, from which many professional sports operators should be able to benefit in the future.
Got web crawling needs to address?
Let’s talkTechnologies
Related in Blog

Scala Play vs ASP.NET Web API - Web Frameworks Comparison
Our company has been developing software for more than 12 years. And around a half of our projects are high-load multi-threaded distributed systems. Therefore, our developers use state-of-the-art technologies and latest frameworks in the process. In this article, we will focus...
Read More
How to Crawl a Protected Website: In-Depth Look
Web crawlers are programs for mass downloading and processing of Internet content. They are also often called “spiders,” “robots,” or even just “bots.” At its core, a crawler does the same things as any ordinary web browser: it sends HTTP requests to servers and retrieves content...
Read More
Scala vs Java 8: 10 Important Differences
Lots of Java developers love Scala and prefer it over Java either for new projects, components of existing Java projects or even performance-critical parts of existing Java modules. Thanks to that Scala has made its way to an enterprise world and is gaining popularity day by d...
Read MoreImpressed?
Hire usOther Case Studies
Animatron
Expanded functionality of startup animation maker recognized by business media like Entrepreneur, MonsterPost, and Freelancer

Linktiger
Built broken link checker capable of crawling 3M+ links and used by big names like Hosting.com, Microsoft, and US Department of Transportation
PageFreezer
Developed a website & social media marketing SaaS that became shortlisted as a Red Herring Top 100 Global Finalist