Gigmit
Berlin, Germany




gigmit is an online portal for live music bookings, helping artists book more gigs and promoters find appropriate performers. It uses data-driven algorithms to perfectly match artists with gigs, festivals, and other events, depending on their genre, preferred location, and fanbase.
All CustomersData Mining
We helped gigmit expand their database with new festivals, venues, and associated contact and location info. We used a combination of API requests and HTML parsing to retrieve and organize the data, strictly adhering to their data structure requirements.
Learn moreMedia & Entertainment
We helped gigmit pursue their mission of making the live music business accessible to anyone. By helping them increase and enrich their database, we provided their users with a broader choice of opportunities, which also translates in higher consumer trust and loyalty.
Learn moreChallenge
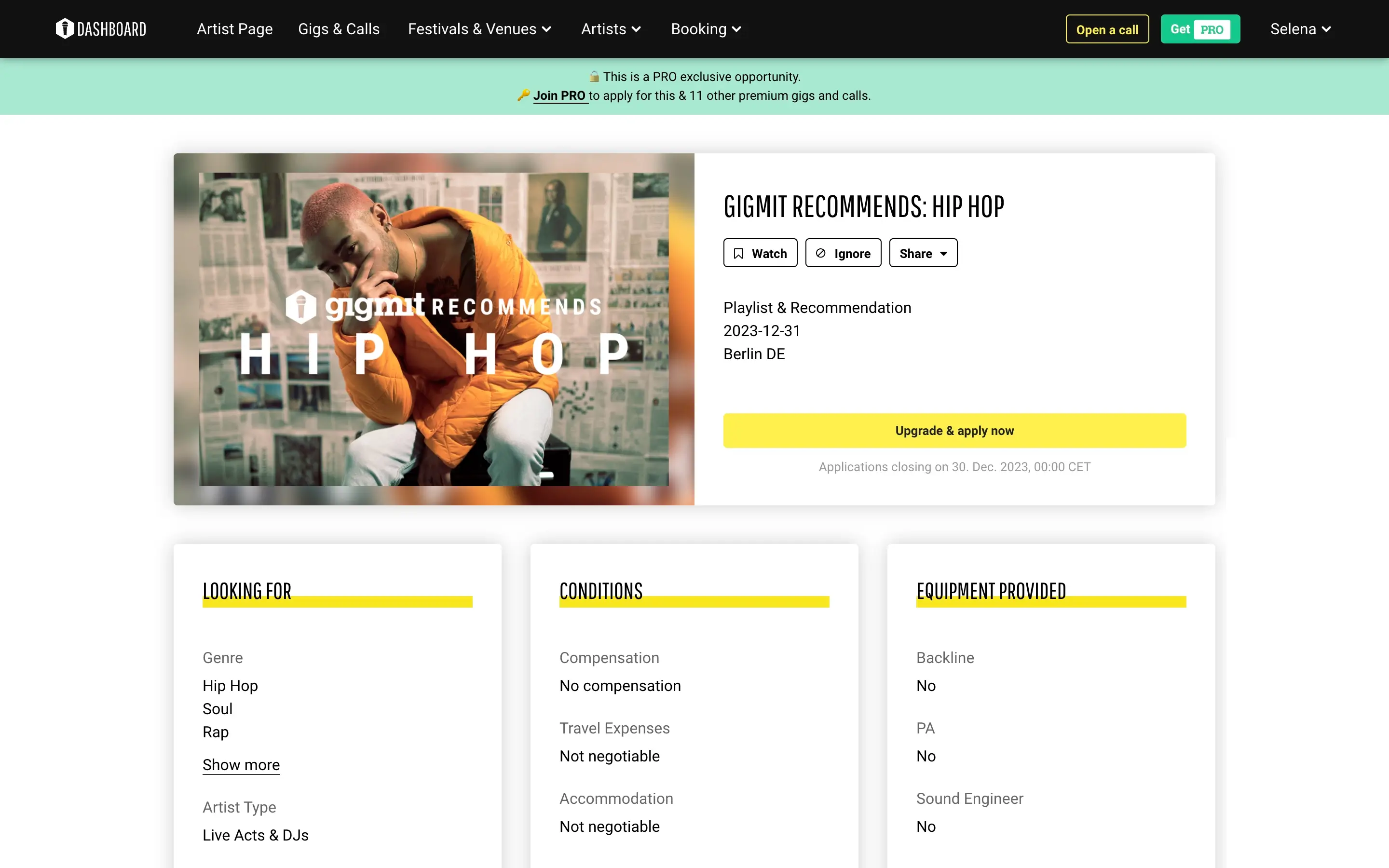
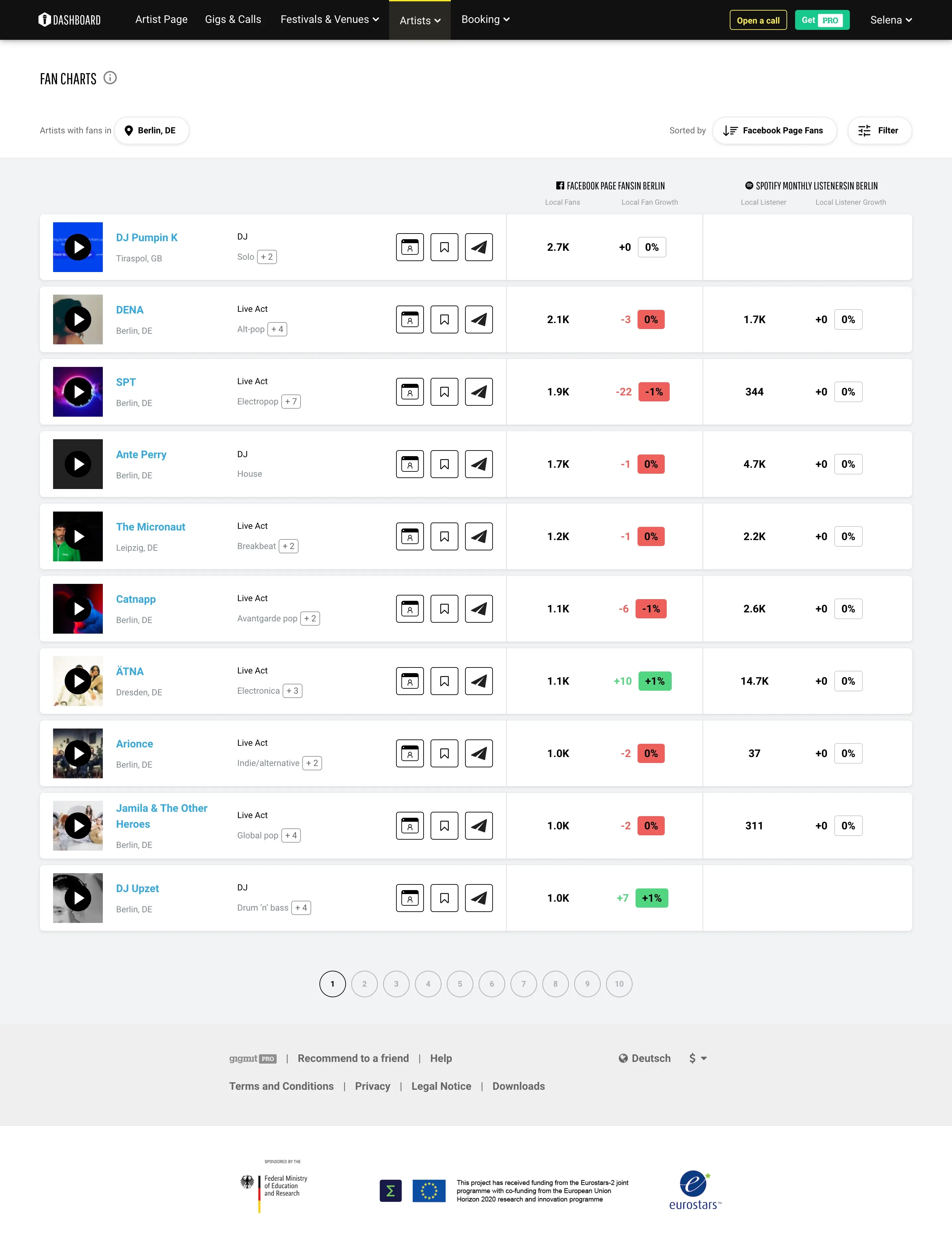
The nature of our client’s business requires continuous data harvesting to ensure the end users have an ever-increasing choice of relevant and up-to-date options. In simple terms, gigmit ensures artists can easily find desirable music festivals, fairs, shows, or special event venues and contact the organizers.
To achieve this goal, gigmit collects publicly available information from a plethora of music & entertainment websites into a single database. Before our partnership, gigmit gathered the necessary data with the help of Scrapy, an open-source web crawler for extracting data with APIs and general-purpose web scraping.
However, they faced certain limitations with this tool, so they turned to Redwerk to help them perform data scraping and parsing of a select number of web resources. Naturally, we were expected to do this in a way that doesn’t harm the operation of the mentioned resources and without getting blocked. Also, we had to work under time constraints.
Solution
The first step was to evaluate the existing web scraping strategy and select a new tech stack that would pose fewer data extraction and display restrictions.
We chose Django REST to build data models and handle interactions with the database. This framework allowed us to organize and manage the collected data efficiently.
We created asynchronous task queues with Celery and RabbitMQ to avoid overloading the servers with API calls. This way, we ensured our requests are processed in an orderly and controlled manner.
Contact information was only sometimes readily available, so we leveraged the power of Hunter.io, an AI-driven email finder.
The biggest challenge was to find the balance between parsing speed and the limits of hosting servers. Still, we ethically collected all the needed data without service disruptions or complaints from the web admins.
Result
With our help, gigmit increased and enriched its database of music festivals, special event venues, pubs, cinemas, art centers, theaters coupled with associated gigs and contact details. We delivered well-structured data in SQL tables and XLSX files in line with the data structure requirements. gigmit’s success as a business relies on up-to-date and relevant data, and we helped them get hold of it in a timely fashion so that their subscribers could see all those opportunities and apply for suitable gigs.
We’re proud that gigmit is expanding to the USA, and we’ll continue supporting them and sharing our tech expertise to ensure their steady growth for the years to come.
In Press
We harness data, and we stand for making that data transparently accessible. At some point we will be able to predict how crowded a concert will be in the future.
Of the platforms, gigmit is making the biggest waves. Founded in 2012, the site is a sort of Tinder for the music industry, bringing together perfectly matched venues and artists.
gigmit was launched under the motto “Simple booking. Booking simply.” on November 11, 2012. For its tenth anniversary, gigmit has 225,000 users from over 120 countries.

A digital solution could simplify the world of live music and help both sides — giving the promoters a more filtered view and helping artists to see where opportunities lie.

Need reliable tool for safe data harvesting?
Talk to expertsTechnologies
 Django REST
Django REST Celery
Celery Hunter.io
Hunter.io PostgreSQL
PostgreSQLRedwerk Team Comment

Oleksandr
Developer
I used a mix of API requests and HTML page parsing to gather the required data. I applied proven strategies to avoid overwhelming the services from which the data was being collected. This project required a bit of problem-solving, but once the right tech stack was selected, everything became very clear and straightforward.
Related in Blog

How to Crawl a Protected Website: In-Depth Look
Web crawlers are programs for mass downloading and processing of Internet content. They are also often called “spiders,” “robots,” or even just “bots.” At its core, a crawler does the same things as any ordinary web browser: it sends HTTP requests to servers and retrieves content...
Read More
How to Choose the Right Tech Stack for Your Project
Software development is a complicated matter. Each project is primarily the concept and the people that bring this concept to life. Deadlines, resources, and of course, technologies, are usually defined afterwards. But it doesn’t imply that the choice of technologies is of the le...
Read MoreImpressed?
Hire usOther Case Studies

CDP Blitz
Optimized database & upgraded functionality of media directory hosting over 35K contacts
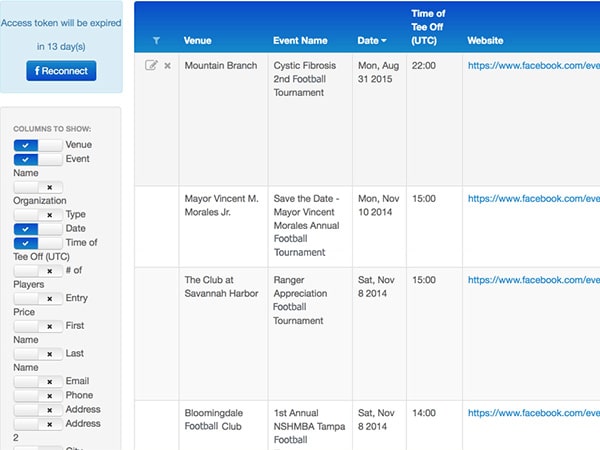
Sports Events Crawler
Automated tedious manual search for sports events with web crawler powered by Facebook API and robust data aggregation