
When we hear “Ruby”, we frequently associate it with “Ruby on Rails”. Rails is a very functional and popular framework that is widely used for building APIs and web-applications. Rails consists of independent gems and ActiveRecord is one of them. This powerful gem simplifies operations with databases, allows to work with them in an object-oriented manner and also makes Ruby on Rails ultimately popular among developers.
But there are numerous bottlenecks in working with ActiveRecord. Many developers often forget, ignore or just don’t know about these issues. At the beginning of project development it doesn’t affect app’s performance, but later on, it might become a pain in the neck.
In our experience, we have dealt with many large projects that included databases, with numerous tables, simple and complex relationships. In one of those projects, we faced the problem: requests to a server called too many queries to a database. And along with the useful operations, there were a lot of unnecessary queries that were significantly slowing down the performance.
When we first looked into the console log, our reaction was a bit overwhelming and fixing all those problems should have taken a lot of time and effort. So, we accepted the challenge to clear the system from those queries, rewrite some of them to optimize the time of execution, reorganize the code and do “everything possible to speed up the system”.
Below you will find typical mistakes and solutions that helped us to accomplish our goals.
To show you the difference in speed of query execution, all the examples described in this article use a simple DB structure that we created for tests. It contains four models: User, Hotel, Company, Country with typical columns. We seeded the DB with test data and added 100k users, 100 hotels, and 1k companies.
We also use Ruby’s Benchmark module for testing the time of execution of our code examples.
Let’s begin.
N+1 query
The easiest and one of the most typical mistakes, that actually slows down the overall system performance. Though it’s quite obvious, we decided to mention this problem, because the ways of resolving it can also affect the result.
As an example, we take a User model and a Country model. The User model has relationship “belongs_to: :country”
The result should be the list of users with their countries.
users = User.limit(10)
users.each do |user|
puts “#{user.full_name} - > #{user.country.name}”
end
When you just start to work with RoR at first you think of this code as “Wow!!! It looks so simple and neat. And it works!”.
But let’s take a closer look. On every loop iteration, RoR calls for SQL query to find a country which relates to a user of a current iteration. So, it calls for 1 query to load users, and 10 queries to load countries on every loop.
We can easily optimize this problem processing the list with two queries:
Users.includes(:country).each do |user|
puts “#{user.full_name} - > #{user.country.name}”
end
At this point numbers might seem very small, but this difference will be as big as bigger will be your amounts of data and load on servers.
Though, this mistake seems typical and easy, it’s crucial to avoid it. You can find the detailed description of this problem in the official Ruby on Rails documentation.
Using JOINS to prevent n+1 query
ActiveRecord has a JOINS method. When we use it, ActiveRecord will join the passed table in the query (or, depending on the syntax you use, it will add the passed JOINS string to the query). Usually JOINS is used for adding clauses to queries.
Like this:
staff = User.joins(:hotel).where("hotels.name like '%Rixos%'")
Let’s check how the query results look:
staff.each do |user|
puts “#{user.full_name} - > #{user.hotel.name}”
end
Look at the logs: JOINS doesn’t load relationships and it is used only for filtering data on a related table. Utilizing this code we’ll get back to n+1 problem described above.
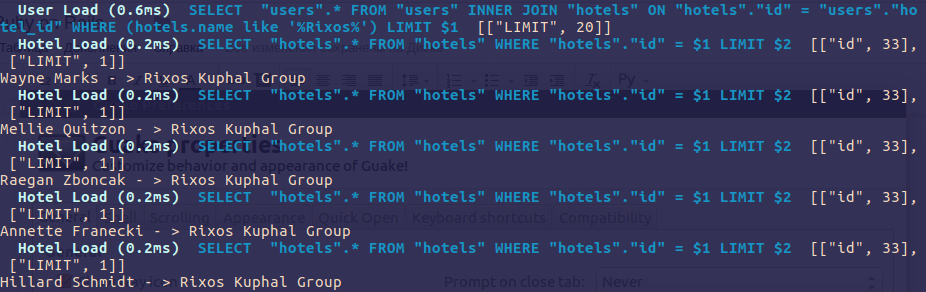
Using INCLUDES instead of using SELECT+JOINS
When you load some records and relationships you often need only one or couple of fields from a related table(s).
users = User.includes(:hotel).limit(20)
users.each do |user|
puts "#{user.full_name} - > #{user.hotel.name}"
end
The problem is in a fact that Rails allocates memory for every loaded field. In some cases related table contains many columns and stores lots of data. So why should you load that unnecessary data if you need just one field (like in the example). You can rewrite the code as follows:
users = User.select('users.*, hotels.name as hotel_name').joins(:hotel).limit(20)
users.each do |user|
puts "#{user.full_name} - > #{user.hotel_name}"
end
COUNT/SIZE/LENGTH on loaded objects
One of the basic tasks is to show a count of some records. There are three different methods to do this: COUNT, SIZE, LENGTH.
And all these methods work in different ways:
- LENGTH loads all the records from the DB (if they haven’t been loaded yet) and calculates their size
- COUNT runs SQL query to calculate the count of records in DB
- SIZE checks if the records have been loaded – calls for the LENGTH method for the scope, otherwise runs a SELECT COUNT(*) query.
So if you are absolutely sure that you don’t need a list of scoped records then you should better use COUNT. If you don’t know whether the data will be loaded or not then use SIZE method. This will save you from excessive queries.
In addition we would like share a little trick with you. Imagine you have a scope, and you know that you need to load data from that scope and calculate its count. But first we want to get the count of records.
users = User.where(hotel_id: 1)
users_count = users.size
users.each do |user|
puts “#{user.full_name}”
end
Here are the logs of execution:
SELECT COUNT(count_column) FROM (SELECT 1 AS count_column FROM "users"
WHERE "users"."hotel_id" = 1) subquery_for_count
SELECT "users".* FROM "users" WHERE "users"."hotel_id" = 1
But you can actually do it with one, more optimised query. All you need to do is just add a LOAD method to the scope. Scoped records will be loaded immediately and SIZE method will not run additional SQL query.
users = User.where(hotel_id: 1).load
users_count = users.size
users.each do |user|
puts “#{user.full_name}”
end
Using this code there would be only one query in logs:
SELECT "users".* FROM "users" WHERE "users"."hotel_id" = 1
This trick is relevant in situations when we load scoped data in any case, and do not add additional scopes below.
Using calculations on Ruby side
Another popular task is to display some complex information about a user, that can’t be loaded from the DB in the condition is which it is stored.
For example, let’s take two models – User and Company with many-to-many associations. In addition User model belongs to Hotel model. We want to output a count of unique users’ by hotels by every company.
You can calculate that in Ruby like this:
companies = Company.includes(:users).limit(100)
companies.each do |company|
puts company.users.map(&:hotel_id).uniq.count
end
And we can do the same calculations, but processing the count on the SQL side:
companies = Company.limit(100)
.select('companies.*, companies_hotels.hotels_count as hotels_count')
.joins('
INNER JOIN (
SELECT companies_users.company_id,
COUNT(DISTINCT users.hotel_id) as hotels_count
FROM users
INNER JOIN "companies_users" ON "users"."id" = "companies_users"."user_id"
GROUP BY companies_users.company_id
) as companies_hotels ON companies_hotels.company_id = companies."id"
')
companies.each do |company|
puts company[:hotels_count]
end
The increase in performance appears because all the calculation are performed on the SQL side, and you don’t load unnecessary data from the database.
Active record callbacks abuse
A callback in ActiveRecord models is a very powerful tool that helps to manage a behavior of entities. But overusing callbacks can significantly slow down the system.
When we add a callback to a model, it is triggered for every event (related to that callback), but some of the calls may be redundant. They do no useful actions and may, for example, run useless SQL queries, do some unnecessary calculations etc. So when you add a callback to a model you must first think if this callback is really necessary for every event execution.
To prevent this situation you can move the code of callbacks to methods or classes and run them only when it is really necessary. This really cleans and speeds up your system.
Summary
As you see, there are many approaches to implement any basic tasks with Ruby on Rails, but not each of them is useful. Choosing a correct solutions will definitely speed up your application and save you from painful afterwards optimization.
For those who prefer to rely on innovative services, there is a great tool that helps to prevent some of the described above mistakes. It is called Bullet and you can find it here: https://github.com/flyerhzm/bullet
About Redwerk
If you are looking for skilled outsource developers, Redwerk is the right place to call on. We offer high-quality outsourcing software development services based on our vast experience of working with different programming languages and technologies. Whether if you need database creation or Ruby on Rails development services, our team will be happy to be involved and become a part of your project. We are also recognized as a top Ruby on Rails Companies on DesignRush.


